

US Bank
Built a team of 30 citizen developers across 2 departments (Risk & Compliance and Process Excellence) to scale across the bank with use cases covering DACA , Post Petition Fee Notice, Reaffirmation Agreements and Consumer lending document intake.
Case Study
Marsh
Centralized operations into lower cost geographies, created its own IDP CoE and gained access to mission critical data from unstructured complex policies, slips, proposal forms, financial statements, often as large as 600 pages, from 475+ different carriers with 50+ coverages across 150+ data fields. Case StudyUSC
Makes faster payments to vendors with no errors while processing 300,000 invoices in various forms/ year (scanned and/ or handwritten) with over 10,000 a week during peak volume, from 25,000 vendors.Case Study
Unilever
Data Scientists get key information from certificates of analysis to ensure product quality, optimize manufacturing processes, predict quality issues, manage suppliers, and ensure regulatory compliance.Case Study
Scoot
Scales their operations by managing timely and accurate processing of ~2000 invoices/ per month, which could be 100-200 pages each, received from 1000+ suppliers globally from 60 destination they fly to. Watch Video



Enhanced Productivity and Efficiency
CMR+ streamlines workflows, eliminates manual data entry, and frees up employees to focus on higher-value tasks.

Scalability and Growth
CMR+ can handle increasing document volumes and adapt to evolving business needs, supporting organizational growth.

Compliance and Security
CMR+ ensures data privacy, adheres to regulatory requirements, and provides audit trails for document processing activities.

Time and Cost Savings
CMR+ automates manual document processing tasks, reducing human error and saving valuable time and resources.

Improved Confidence in Accuracy
CMR+'s advanced algorithms and machine learning capabilities enhance data extraction accuracy, minimizing the risk of errors and improving overall data quality.



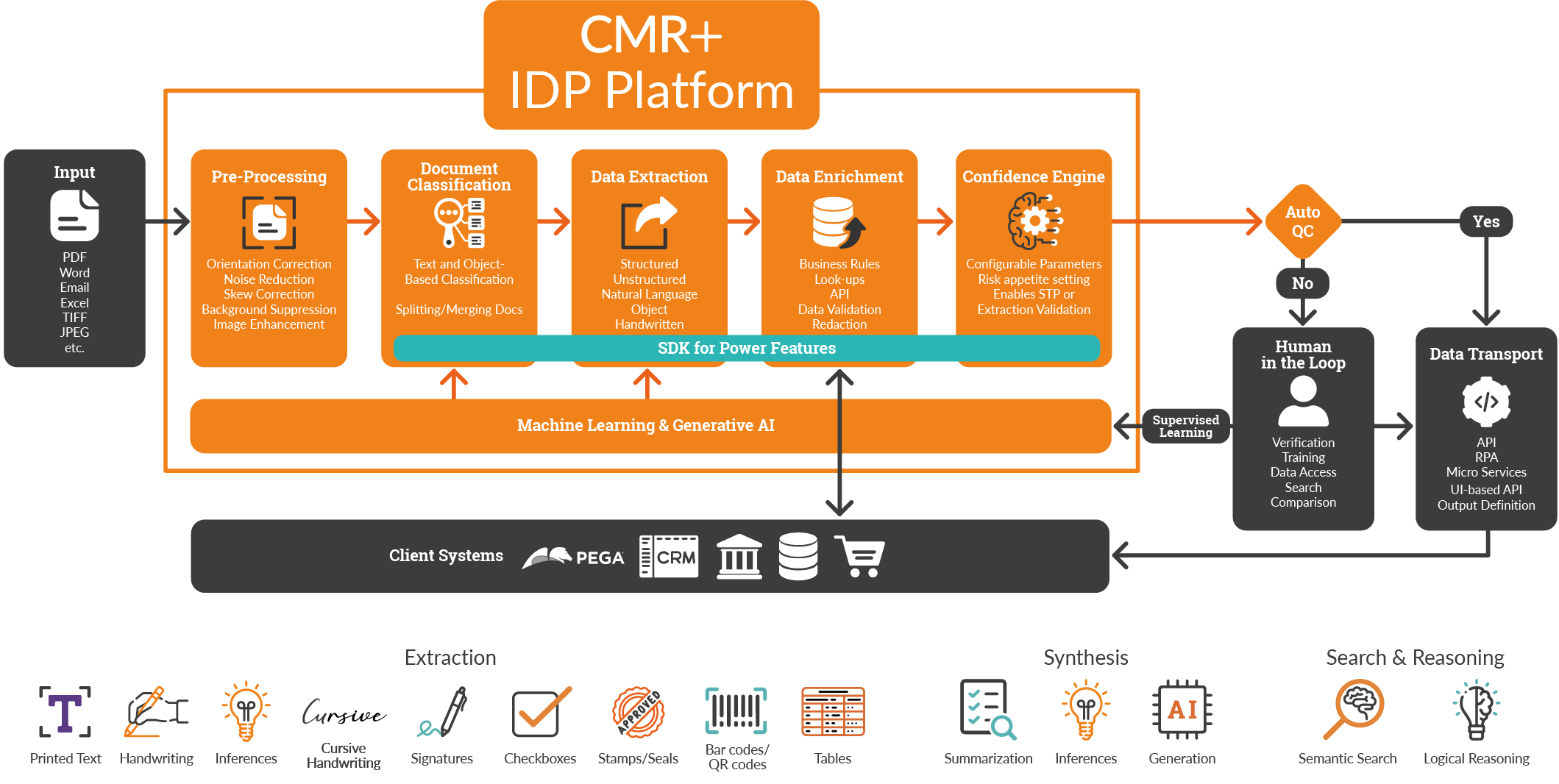
The CMR Process Flow
Process Flow






Intelligent Document Processing





Mentioned in the 2022 Gartner® Market Guide for Intelligent Document Processing Solutions*

Challenger in Document Oriented Text Analytics Platforms Wave 2020 & 2022

Major Contender in Everest Group® IDP PEAK Matrix 2023

Leader for the Second Year in a Row in ISG’s IDP Provider Lens™











{kind=link}